Кто такой SRE инженер?
SRE Engineer — на IT рынке так называют айтишника, который отвечает за надежность и производительность IT-систем в продакшене. Этот специалист несет ответственность за то, чтобы система быстро поднималась, а лучше не "падала".
SRE (Site Reliability Engineering) — это подход к эксплуатации программного обеспечения, который объединяет принципы разработки и системного администрирования. Основная цель — создавать надежные, масштабируемые системы, которые работают стабильно под любой нагрузкой.
SRE — это не просто "продвинутый DevOps". Это отдельная философия, где надежность системы измеряется в метриках, а не в субъективных оценках.
Почему появились SRE?
SRE появился в Google в 2003 году, когда компания столкнулась с проблемами масштабирования своих сервисов. Бен Трейнор, один из создателей SRE, понял, что традиционный подход к эксплуатации не справляется с растущими нагрузками.
Ключевая идея была проста: применить инженерный подход к эксплуатации. Вместо того чтобы просто "тушить пожары", SRE инженеры создают системы, которые предотвращают эти пожары.
Что делает SRE инженер?
1. Надежность системы (Reliability)
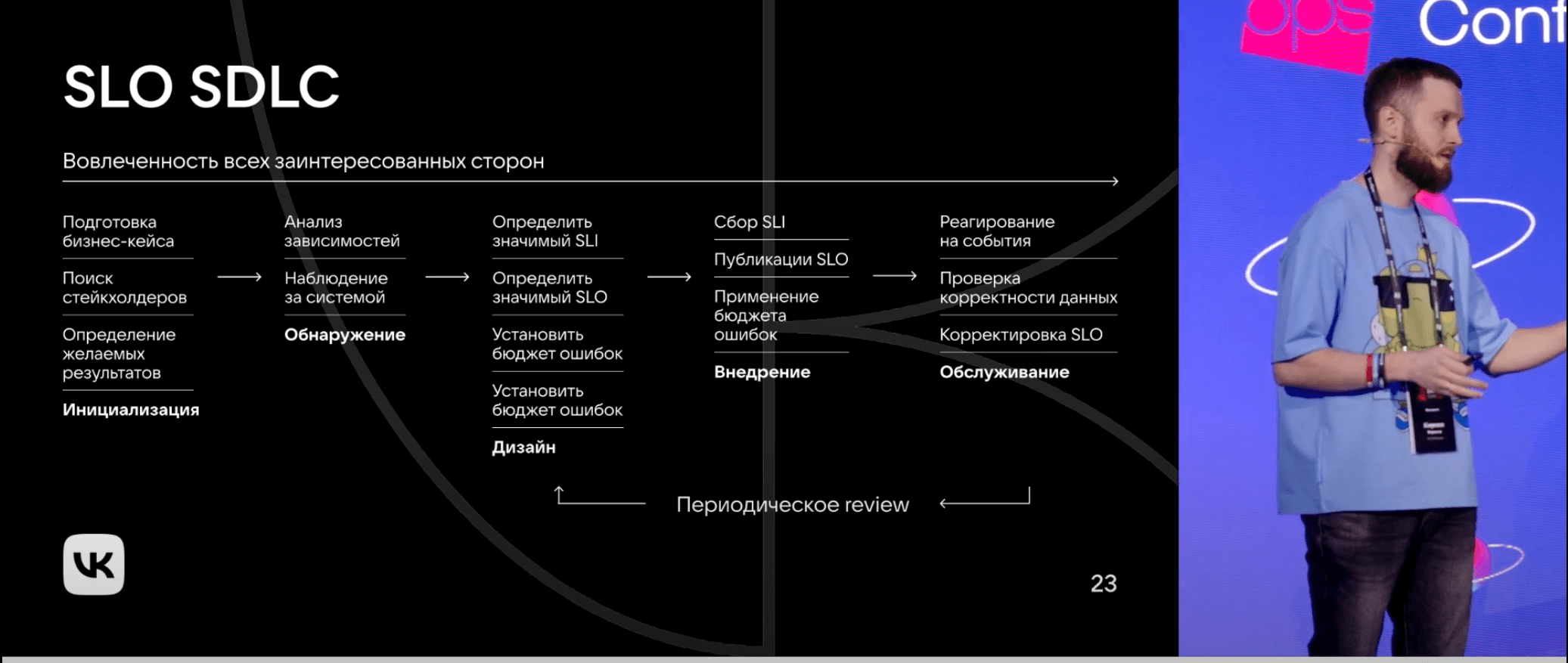
- Устанавливает SLO (Service Level Objectives) и SLI (Service Level Indicators)
- Отслеживает 4 золотых сигнала мониторинга: latency, traffic, errors, saturation
- Создает системы автоматического восстановления
2. Автоматизация операций
- Пишет код для автоматизации рутинных задач
- Создает self-healing системы
- Разрабатывает инструменты для мониторинга и алертинга
3. Управление инцидентами
- Организует процесс реагирования на инциденты
- Проводит post-mortem анализ инцидентов
- Улучшает процессы на основе полученного опыта
4. Производительность и масштабирование
- Оптимизирует производительность систем
- Планирует масштабирование инфраструктуры
- Проводит chaos engineering и нагрузочное тестирование
Попробуй себя в роли SRE
Хочешь стать SRE специалистом? Начни с практики! В нашем тренажере ты можешь попробовать себя в роли SRE инженера и научиться диагностировать реальные проблемы с надежностью систем.
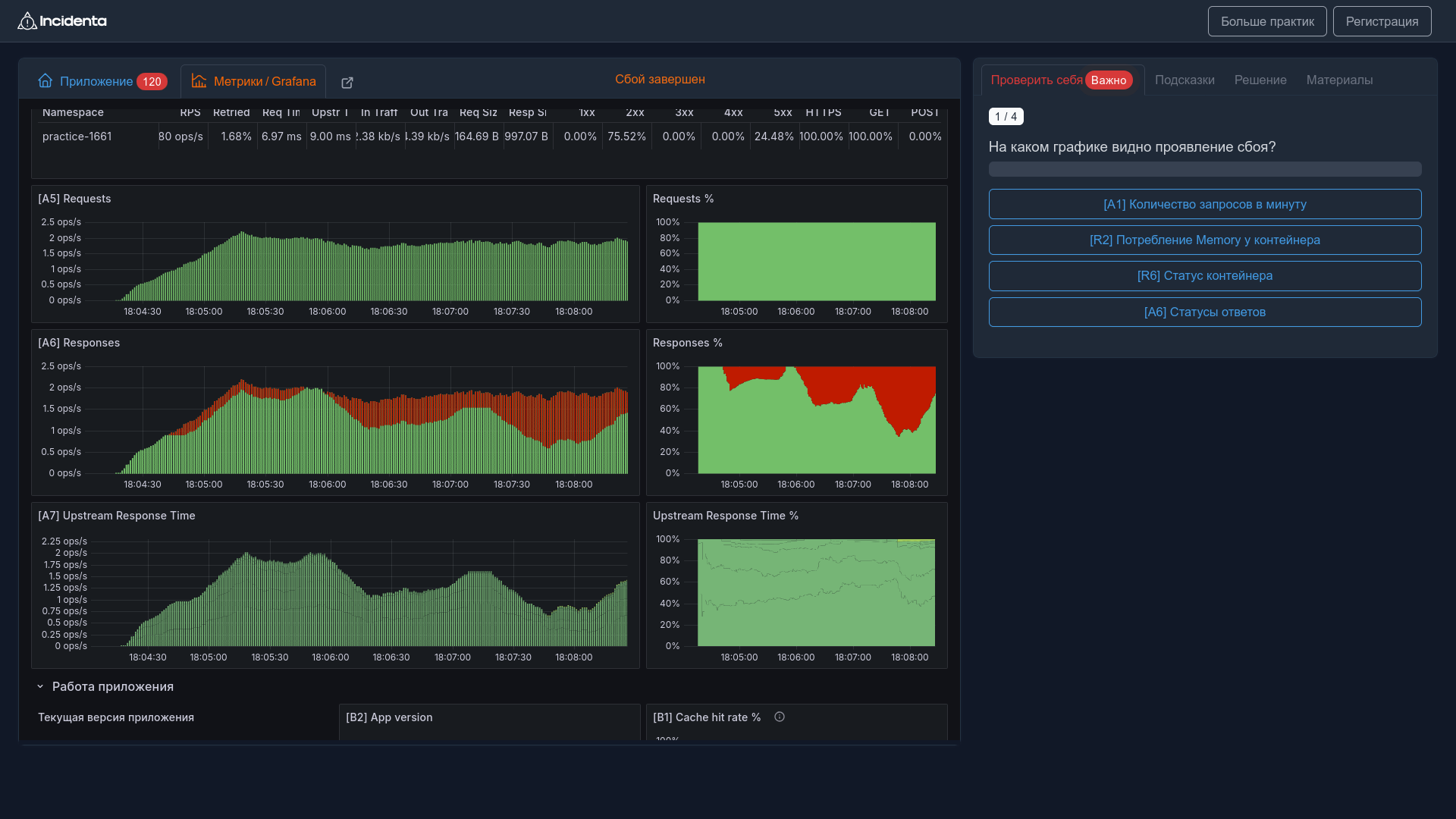
Примеры конкретных задач
- Создай/подбери Grafana дашборды для отслеживания метрик приложения
- Настрой Prometheus алерты при превышении пороговых значений
- Написать скрипт для автоматического перезапуска упавших сервисов
- Подбери оптимальные настройки для Redis/RabbitMQ, чтобы снизить нагрузку
- Собери релевантных сотрудников и реши критический инцидент
- Оцени реализованную архитектуру и опиши узкие места, которые приведут к снижению надежности
Основные инструменты
Значимая часть применяемых инструментов можно посмотреть в Cloud Native Landspace. Например:
- Для экплуатации серверов — Kubernetes, OpenShift
- Для мониторинга — VictoriaMetrics, Grafana, Prometheus, Loki, alert manager
- Для контроля работы — Sentry, PagerDuty, Chaos Mesh
- Базы данных — PostgreSQL, MariaDB, MongoDB
- Очереди и другое — Redis, Kafka
FAQ
Чем SRE отличается от DevOps?
DevOps фокусируется на автоматизации процессов разработки и развертывания, а SRE — на надежности и производительности систем в продакшене. SRE использует инженерный подход с конкретными метриками и целями.
Какие навыки нужны SRE инженеру?
Нужны знания системного администрирования, программирования (например, Python, Go), понимание сетей, баз данных, облачных платформ. Важны soft skills: аналитическое мышление, стрессоустойчивость, умение работать в команде.

Что такое SLO и SLI в SRE?
SLO (Service Level Objective) — это целевые показатели надежности сервиса, например "99.9% доступности в месяц". SLI (Service Level Indicator) — это метрики, которые измеряют эти цели, например время отклика API или количество ошибок 5xx. Подробнее о том, как правильно устанавливать SLO, читай в нашей статье.
Как измерить успех SRE?
Основные метрики: время восстановления (MTTR), время между сбоями (MTBF), доступность сервисов, производительность. Также важно количество автоматизированных операций и время, потраченное на рутинные задачи.
Что такое Error Budget в SRE?
Error Budget — это допустимое количество времени, когда сервис может быть недоступен или работать с ошибками. Например, если SLO = 99.9% доступности, то Error Budget = 0.1% времени (около 43 минуты в месяц).
Как SRE помогает бизнесу?
SRE снижает риски простоя, повышает удовлетворенность пользователей, уменьшает затраты на поддержку. Стабильные системы позволяют бизнесу расти и развиваться без технических ограничений.