Золотые сигналы (Golden Signals) мониторинга — это набор из 4 ключевых метрик, которые позволяют эффективно оценить здоровье IT-системы:
- Latency (задержка)
- Traffic (трафик)
- Errors (ошибки)
- Saturation (насыщение).
Почему именно эти метрики? Google проанализировал тысячи инцидентов и выяснил, что 90% проблем в production можно обнаружить, отслеживая только эти 4 сигнала.
Если ты хочешь выбрать минимальный набор метрик для мониторинга, то это именно те 4, которые нужны. Золотые сигналы дают достаточно данных, чтобы быстро выявлять проблемы и принимать решения на основе SRE-подходов.
Подробнее про каждый сигнал
Latency (Задержка) — время отклика системы
Latency измеряет время, которое требуется системе для обработки запроса. Обычно имеется в виду время обработки HTTP-запроса, но можно применять и для запросов в базу данных.
Ключевые особенности:
- Стоит рассматривать метрику в различных срезах, как минимум, отделить "успешные" и "неуспешные запросы".
- Среднее значение может скрыть плавающие проблемы. Поэтому лучше использовать процентили
- HTTP 500 может обрабатываться быстро, но это не означает хорошую производительность
- Медленная ошибка хуже быстрой ошибки
Практический пример: Если твой API обычно отвечает за 100мс, а внезапно latency вырос до 2 секунд — это первый признак проблем с базой данных или перегрузки сервера.
PromQL для мониторинга latency:
# 95-й процентиль времени ответа HTTP запросов
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
# Среднее время ответа успешных запросов (HTTP 2xx)
rate(http_request_duration_seconds_sum{status=~"2.."}[5m]) / rate(http_request_duration_seconds_count{status=~"2.."}[5m])
# 99-й процентиль времени ответа неуспешных запросов
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket{status=~"5.."}[5m])) by (le))
Traffic (Трафик) — нагрузка на систему
Traffic показывает, какая нагрузка приходится на твою систему. Для веб-сервиса это обычно HTTP-запросы в секунду, для базы данных — транзакции в секунду.
Что измерять:
- HTTP-запросы в секунду для веб-сервисов
- Количество соединений для приложений
- Транзакции в секунду для баз данных
- Объем данных (в мегабайтах и гигабайтах) для стриминговых сервисов
Зачем: каждый сервер и сетевой канал имеет ограничение по пропускной способности. Зная текущую нагрузку и лимиты приложения, можно заранее планировать масштабирование и расширение возможностей.
PromQL для мониторинга traffic:
# Количество HTTP запросов в секунду
sum(rate(http_requests_total[5m])) by (instance, method, status)
# Количество активных соединений к базе данных
pg_stat_activity_count
# Количество транзакций в секунду для PostgreSQL
rate(pg_stat_database_xact_commit[5m]) + rate(pg_stat_database_xact_rollback[5m])
# Количество запросов к Redis в секунду
rate(redis_commands_processed_total[5m])
Errors (Ошибки) — процент неуспешных запросов
Errors отслеживают долю запросов, которые завершаются неудачно. Это могут быть явные ошибки (HTTP 500) или неявные (HTTP 200 с неправильным содержимым).
Типы ошибок:
- Явные: HTTP 500, 404, таймауты соединения
- Неявные: HTTP 200 с неправильным содержимым
- По политике: запросы, превышающие установленный SLA
- По размеру ответа: размеры тела ответа
С чего начать: начни с мониторинга количества 5xx ошибок и 404/403 ошибок. Это покроет 90% случаев проблем в production.
PromQL для мониторинга errors:
# Процент HTTP ошибок (4xx + 5xx)
sum(rate(http_requests_total{status=~"4..|5.."}[5m])) / sum(rate(http_requests_total[5m])) * 100
# Количество 5xx ошибок в секунду
sum(rate(http_requests_total{status=~"5.."}[5m])) by (instance, endpoint)
# Процент ошибок по эндпоинтам
sum(rate(http_requests_total{status=~"5.."}[5m])) by (endpoint) / sum(rate(http_requests_total[5m])) by (endpoint) * 100
# Ошибки подключения к базе данных
rate(pg_stat_database_deadlocks[5m])
Saturation (Насыщение) — объем работы в очереди на обработку
Saturation является менее интуитивным понятием, но давай попробуем разобраться.
Утилизация ресурсов показывает насколько активно используется ресурс (измеряется обычно в %): сколько CPU, памяти, дискового пространства, сетевой пропускной способности используется. Поддержание собственной работы системы (ожидание запросов, опрос устройств, работа операционной системы) уже потребяет ресурсы, при этом "полезной" для нас работы может не совершаться.
Поэтому Saturation обычно хоть и стоит ногами на утилизации, но работает с более высоко-уровневыми понятими. Например:
- Количество запросов
- Количество задач в очереди
- Времена задержки ответов
Важно знать:
- Большинство систем деградируют до достижения 100% утилизации, обычно на уровне 75-85%
- Рост latency часто является ранним индикатором saturation
- Настрой алерты на значения утилизации (например, 70-80% для CPU), чтобы увидеть это самому.
Практический совет: Следи за 99-м процентилем latency/времени ответа — это даст раннее предупреждение о насыщении.
PromQL для мониторинга saturation:
# Утилизация CPU (процент)
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
# Утилизация памяти (процент)
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100
# Утилизация диска (процент)
(node_filesystem_size_bytes - node_filesystem_free_bytes) / node_filesystem_size_bytes * 100
# Количество активных соединений к базе данных
pg_stat_activity_count
# Очередь запросов в приложении
rate(http_requests_in_flight[5m])
Как применять золотые сигналы на практике
Понимание 4 золотых сигналов — это основа эффективного мониторинга систем. Но что делать, когда метрики показывают проблему? Попробуй демо-сценарий с реальным инцидентом и научись диагностировать проблемы на практике.
Практические советы по внедрению
- Начни с одного сервиса — выбери критически важный сервис и настрой мониторинг 4 сигналов
- Установи базовые пороги — на основе текущих показателей определи нормальные значения
- Создай простой дашборд — визуализируй все метрики на одном экране с помощью PromQL запросов выше
- Настрой алерты — но не слишком чувствительные, чтобы избежать "alert fatigue"
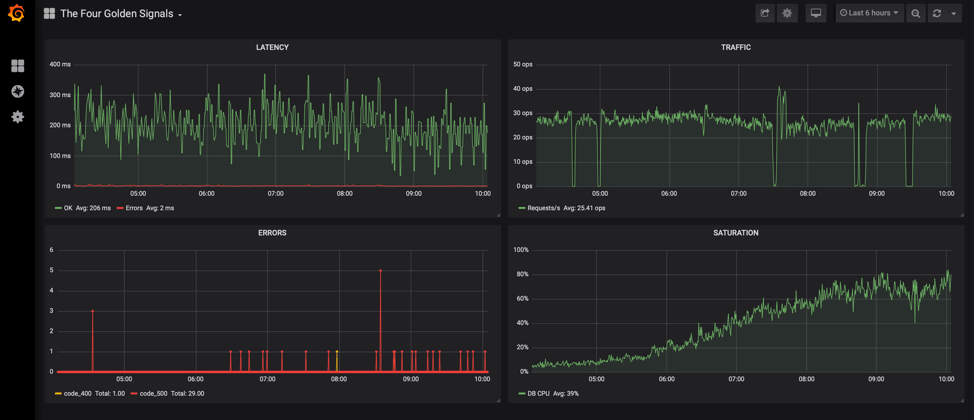
Пример дашборда Golden Signals в Grafana
Создай дашборд с 4 панелями, используя эти базовые PromQL запросы:
# Панель 1: Latency (95-й процентиль)
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
# Панель 2: Traffic (запросы в секунду)
sum(rate(http_requests_total[5m]))
# Панель 3: Errors (процент ошибок)
sum(rate(http_requests_total{status=~"4..|5.."}[5m])) / sum(rate(http_requests_total[5m])) * 100
# Панель 4: Saturation (CPU утилизация)
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
Изучи реальные сбои и развивай навыки SRE
Мониторинг золотых сигналов помогает обнаружить проблему, но нужно уметь ее решать. Изучи коллекцию тренировок с реальными инцидентами и научись быстро диагностировать и устранять сбои в production.
FAQ
Как связать золотые сигналы с бизнес-метриками?
Создай mapping между техническими и бизнес-метриками:
- Latency → время конверсии пользователей
- Errors → потерянные продажи
- Saturation → cost per request
Это поможет обосновать инвестиции в надежность.
Как адаптировать сигналы для разных типов систем?
Да, концепция остается той же, но метрики могут отличаться:
- Для batch-систем: throughput вместо latency
- Для систем хранения: IOPS и durability
- Для ML-систем: accuracy и bias