Современный IT строится на множестве компонентов: баз данных, кэши, очереди, внешние API и т.д. Инструменты мониторинга помогают видеть, что происходит в системе в реальном времени, быстро находить корень проблемы при сбоях.
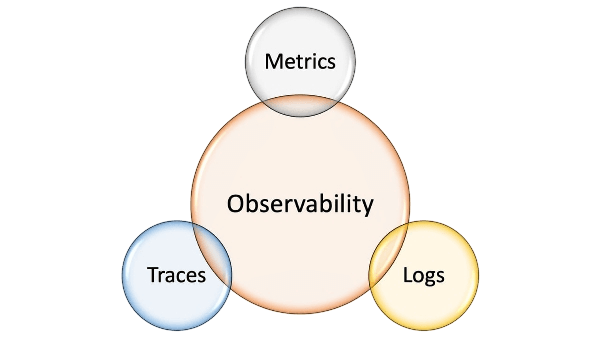
Компоненты мониторинга
Метрики — числовые показатели производительности (CPU, память, время ответа API)
Логи — текстовые записи событий и ошибок
Трейсы — данные о прохождении запроса через систему
Алерты — уведомления о критических событиях
Современный мониторинг строится на принципе "observability" — способности понять внутреннее состояние системы по внешним наблюдениям. Это как рентген для IT-систем.
Метрики (Metrics)
Числовые данные о производительности системы:
- Системные метрики: CPU, память, диск, сеть
- Бизнес-метрики: количество заказов, активных пользователей
- Прикладные метрики: время ответа API, количество ошибок
Логи (Logs)
Структурированные записи событий. Системы логирования позволяют:
- Быстро искать по миллионам записей (нормально, когда приложение в день выдает не менее 1 ГБ логов)
- Анализировать паттерны и аномалии
- Коррелировать события из разных источников (проводя поиск по ключам из логов)
Трейсы (Traces)
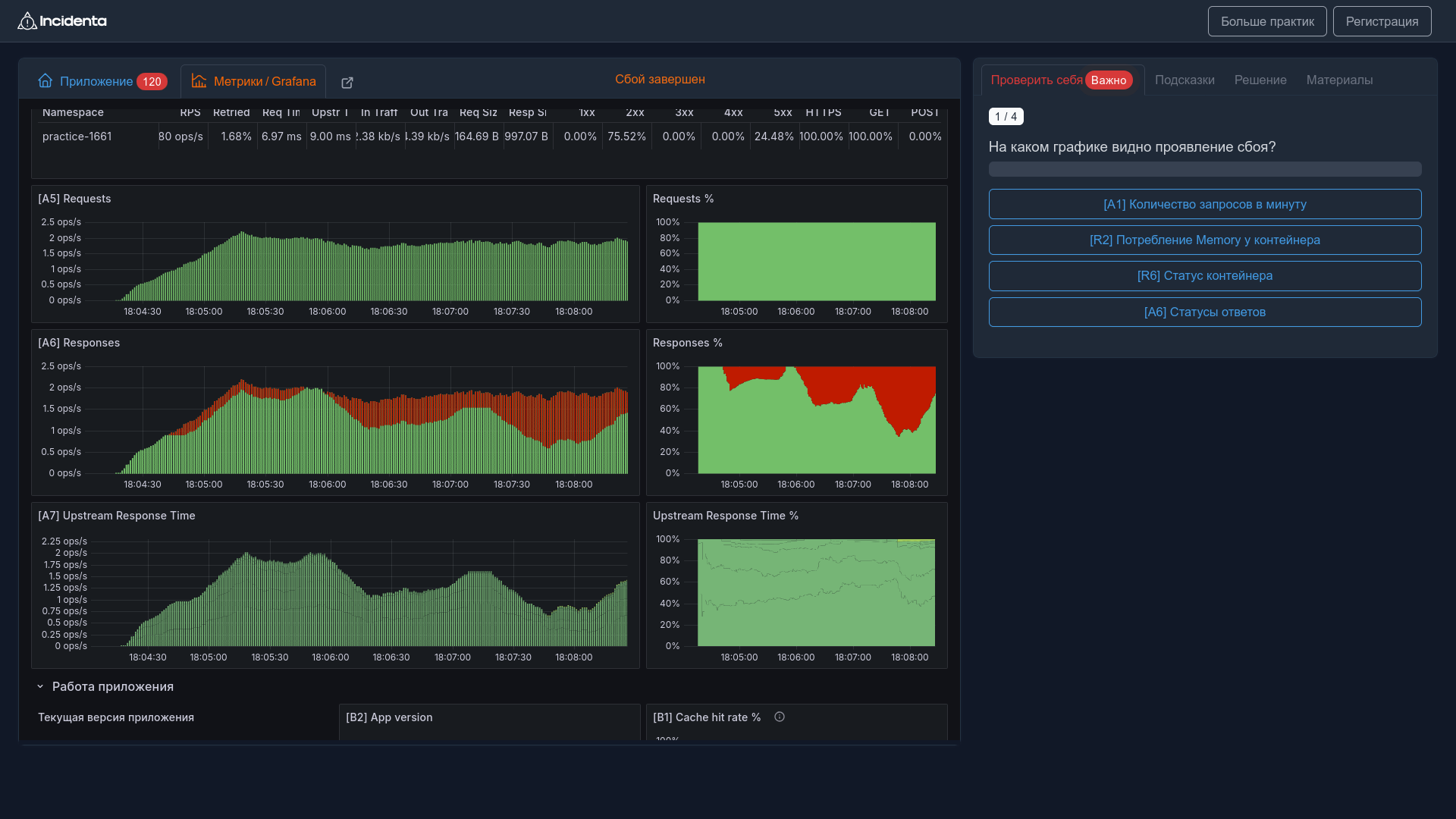
Данные о прохождении запроса через все компоненты системы. Показывают в собственном UI:
- Где именно происходит задержка
- Какие сервисы вызывают друг друга
- Полную картину выполнения запроса
Готов к реальным инцидентам?
Понимание инструментов мониторинга критически важно, но что делать, когда система все-таки падает? Попробуй демо-сценарий и убедись, насколько эффективным может быть обучение на практике.
Популярные инструменты мониторинга
Сбор метрик
Prometheus/VictoriaMetrics/Thanos — наиболее распространенное решение для сбора и хранения метрик
- Pull-модель сбора данных, приложению достаточно выставить метрики наружу, система их заберет
- Большой набор готовых решений для сборки метрик с баз данных, очередей и т.д.
- Язык запросов PromQL, который является одним из стандартов работы с метриками
- Нативная интеграция с Kubernetes
Zabbix/Nagios — второе по популярности решение, часто используется в системах без облаков
- Поддерживает сбор метрик с разных сущностей: от серверов и сетевого оборудования до приложений и баз данных
- Поддержка готовых отчетов для анализа исторических данных
- Поддержка интеграции с разными внешними системами
Визуализация
Если у системы мониторинга нет собственного UI, то скорее всего будет Grafana.
Grafana — лидер в области визуализации метрик
- Богатые возможности создания дашбордов
- Поддержка множества источников данных
- Система алертов
- Шаблоны для типовых сценариев
Логирование
Систему сбора логов можно построить самостоятельно из своих компонентов, однако чаще всего встречаются три комбинации:
1. ELK Stack (Elasticsearch, Logstash, Kibana)
- Elasticsearch: поисковая система для логов
- Logstash: обработка и обогащение логов
- Kibana: визуализация и анализ
В ELK каждая из букв может быть заменена на другое решение:
- Elasticsearch на OpenSearch
- Logstash на Vector, Fluentd и множество других
- Kibana на Grafana
Для построения запросов используется язык Lucene, логика построения повторяет SQL
2. Grafana Loki — простая в настройке и использовании система логов
Нативно встроена в Grafana, позволяет строить графики.
Для построения запросов используется LogQL, логика построения повторяет grep
3. ClickHouse + Kafka + Vector
- ClickHouse — хранилище логов (структурированных)
- Kafka — инструмент приема логов для последующего хранения
- Vector — система сбора логов (и метрик) с возможностью фильтрации
Для построения запросов используется (урезанный) SQL, логика построения повторяет SQL
Трейсинг
Jaeger/OpenTracing System — распределенная система трейсинга
- Отслеживание запросов через микросервисы
- Визуализация зависимостей
- Анализ производительности
Как выбрать инструменты мониторинга
Оцени масштаб системы
- Небольшие проекты: Prometheus/VictoriaMetrics + Grafana
- Средние проекты: ELK Stack/Loki + Jaeger
- Крупные проекты: комбинированные решения с кастомными компонентами
Учитывай технический стек
- Kubernetes: Prometheus + Grafana + Jaeger
- AWS: CloudWatch + X-Ray
- Azure: Application Insights
- GCP: Stackdriver
FAQ
Какие метрики критически важны для любого проекта?
Обязательные метрики:
- Доступность сервисов (uptime)
- Время ответа (response time)
- Количество ошибок (error rate)
- Использование ресурсов (CPU, память, диск)
Бизнес-метрики:
- Количество активных пользователей
- Количество транзакций (оплаты, например)
- Конверсия ключевых действий (регистрации, оплаты, переходов на определенную страницу)
Как мониторинг связан с SRE практиками?
Мониторинг — основа SRE:
- SLO/SLI измеряются через метрики
- Error Budget рассчитывается на основе данных мониторинга
- Postmortem анализ использует логи и трейсы
- Chaos Engineering требует детального мониторинга для оценки воздействия