Есть три основных варианта настроить алертинг на базе метрик из Prometheus/VictoriaMetrics:
- Alertmanager — решение от Prometheus
- Grafana Alerting — встроенная система в Grafana
- VictoriaMetrics Alert (vmalert) — легковесная альтернатива
Каждый имеет свои плюсы, а в целом можно использовать любой. В конце концов, важно не то, каким инструментом ты делаешь алерты, а то, как быстро ты реагируешь на инциденты.
Варианты
Alertmanager — классическое решение от Prometheus
Alertmanager — это официальный компонент Prometheus, специально созданный для обработки алертов. Он получает алерты от Prometheus сервера и отвечает за их группировку, подавление дублирующих уведомлений и доставку через различные каналы.
Алерт в терминах Prometheus/VictoriaMetrics - это определенный query, на значения которого можно повесить обработку. Или записать обратно в хранилище.
Ключевые возможности:
- Группировка алертов по меткам (labels)
- Интеграция с Slack, Telegram, email, webhook'и
- Роутинг алертов в зависимости от условий
- Подавление повторных уведомлений (inhibition)
- Шаблонизация сообщений
- Возможность описывать алерты в YAML (т.е. хранить в репозитории)
Alertmanager работает как отдельный сервис и принимает алерты от одного или нескольких Prometheus серверов. Это классическая архитектура, которая используется в большинстве промышленных инсталляций.
Grafana Alerting — альтернатива
Grafana с версии 8.0 получила встроенную систему алертов (они купили полу-готовое решение), которая может работать не только с Prometheus, но и с множеством других источников данных. Это решение "all-in-one", где алерты настраиваются прямо в интерфейсе дашбордов.
Преимущества Grafana Alerting:
- Единый интерфейс для дашбордов и алертов — не нужно переключаться между разными инструментами
- Визуальный конфигуратор правил с возможностью предпросмотра результатов
- Встроенные интеграции для отправки уведомлений: Telegram, PagerDuty, Slack, email и множество других
- Возможность тестирования алертов прямо в UI без влияния на продакшен
- Поддержка множественных источников данных — можешь делать алерты по логам, метрикам из БД, трейсам
Недостатки:
- Настраивается через UI, что усложняет версионирование и автоматическое развертывание
- Сложнее масштабировать на множественные кластеры
- Больше потребляет ресурсов по сравнению с Alertmanager
VictoriaMetrics Alert (vmalert) — специализированное решение
Для пользователей VictoriaMetrics существует vmalert — легковесный компонент алертинга, который может работать как с VictoriaMetrics, так и с обычным Prometheus. Он совместим с правилами Prometheus и может отправлять алерты в Alertmanager.
Особенности vmalert:
- Низкое потребление ресурсов, как и в целом самой VictoriaMetrics — идеально для high-load систем
- Полная совместимость с Prometheus alert rules (можно перенести правила из Prometheus в vmalert, обратно — не всегда)
- Возможность записи метрик обратно в VictoriaMetrics для дальнейшего анализа
- Встроенная поддержка HA режима для критически важных систем
- Поддержка recording rules для предвычисления сложных метрик
Научись быстро диагностировать проблемы в продакшене
Настроить алерты — это только половина дела. Важно уметь быстро разбираться с инцидентами, когда они случаются. Попробуй демо-тренировку и прочувствуй, как проходит диагностика реального сбоя в безопасной среде.
Пример алерта для Alertmanager
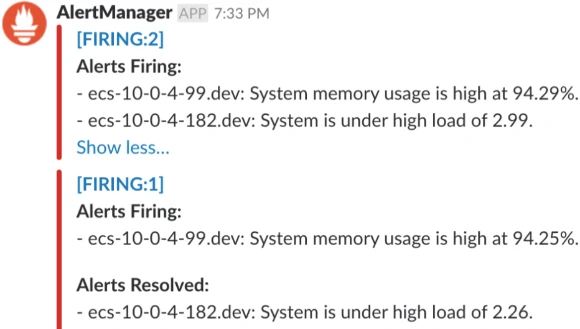
# Пример правила для Prometheus
groups:
- name: basic-alerts
rules:
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.1
for: 2m
labels:
severity: critical
annotations:
summary: "High error rate detected"
description: "Error rate is {{ $value }} errors per second"
Алерты можешь базировать на золотых сигналах мониторинга: задержке, ошибках, трафике и насыщении. Это покроет 80% потребностей в алертинге для большинства сервисов.
FAQ
Что лучше: Alertmanager или Grafana Alerting?
Выбор зависит от твоей архитектуры:
Используй Alertmanager, если:
- Тебе важно иметь версионирование алертов (запросов в них) и хранить в Git'е
- Тебе важно обновлять алерты из 1 места
- У тебя в основном используются Prometheus-like решения.
Используй Grafana Alerting, если:
- Нужен единый UI для дашбордов и алертов
- Есть множественные datasources (не только Prometheus)
- Настраивают алерты не DevOps, а например, QA
Сколько алертов должно быть в системе?
Нет универсального числа, но есть принципы:
- Лучше меньше, да лучше — каждый алерт должен требовать действий. Учитывай критичность и другие параметры инцидентов.
- Если алерт срабатывает, но не требует немедленных действий — это кандидат на удаление или понижение приоритета.
- До 5-10 алертов, а лучше 2-3 алертов за рабочий день, которые требуют действий — это терпимое значение.
- Помни про alert fatigue: слишком много шумных уведомлений приводят к игнорированию даже критических проблем.
Как избежать alert fatigue?
Alert fatigue — это когда команда перестает реагировать на алерты из-за их избытка. Способы борьбы:
- Настраивай алерты только на симптомы, а не на причины
- Используй группировку по времени и меткам
- Настрой escalation — критические алерты должны "шуметь" громче
- Регулярно пересматривай и удаляй неактуальные правила
- Используй разные каналы для разного уровня критичности