Мониторинг и Наблюдаемость — два термина, которые применяются, чтобы оценить "что происходит?" с системой (мониторинг) и "почему это происходит?" (наблюдаемость):
- Мониторинг говорит нам, что что-то сломалось
- Наблюдаемость позволяет погрузиться в детали и разобраться что именно и как.
Чтобы это удавалось делать, необходимо собирать, хранить и обрабатывать различные виды данных: обычно метрики, логи, трейсы. Но данные скорее являются следствием, основа — это вопрос "WHAT THE F..." или делая литературную озвучку Lost — "Что случилось?" или даже "Что может случиться". С этого и начнём рассказывать про эту тему.
Что не измерено, тем сложно/нельзя управлять (с) Питер Друкер. Самая популярная цитата по теме.
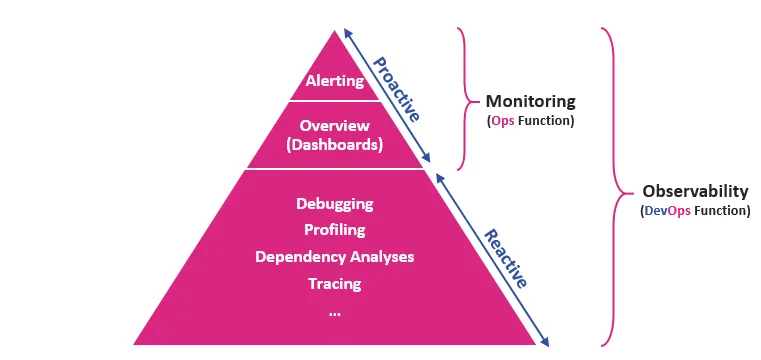
Что-то сломалось. Зачем нужен мониторинг
Мониторинг показывает, что ошибка есть, но не позволяет "дебаггером" ее анализировать
IT-продукты создаются командами, которые передают результат между друг другом, например согласно
Software Development Life Cycle:
- QA команда проверяет реализацию на соответствие требованиям, убеждается, что нет блокирующих изъянов в продукте.
- Dev команда реализует требования, учитывая узкие места и corner-cases.
- Ops команда обеспечивает доступ пользователей к продукту согласно их ожиданий.
Каждый знает что он делает, но в моменты сбоя системы становится ясно, что общую картину никто не держит и на выяснении кто прав, а кто виноват уходит множество времени. Именно здесь и возникает мониторинг, который позволяет оценить корректность работы системы и из чего состоит:
- Какие основные процессы/системы?
- Как можно понять, что процесс выполняется корректно?
- Какие данные теоретически существуют, чтобы это посчитать в числах?
- Кто поставщик данных? Какая частота данных? Полнота? Корректность?
- Какая альтернатива есть, чтобы проверить работу процесса?