О чем это доклад
Обзор доклада Кирилла Борисова с DevOpsConf 2024 про то, как можно определять целевой уровень хорошей работы системы. В прошлом можно было просто сказать "система работает стабильно" и этого было достаточно. Сегодня бизнес требует конкретных цифр и обоснований. SLO появились как ответ на потребность в измеримом качестве услуг.
Контекст
Современный IT — это гора различных метрик, терминов. Не принято работать по наитию/я так чувствую. "Покажи мне свои цифры, а я скажу кто ты". Эксплуатация айти-продукта связана с терминами SLO/SLI/SLA, о которых Кирилл рассказывает подробно.

SLI (Service Level Indicator) — это (часто) набор метрик, которые позволяют оценить качество сервиса. Например, скорость загрузки страницы = значение 95 процентиля скорости ответов запроса /blog/1 за последние 15 минут.
SLO (Service Level Objectives) — это (часто внутренние) цели выраженная количественно, которые определяют, насколько хорошо должен работать сервис с точки зрения заказчиков/пользователей. Например, 99.99% времени скорость загрузки страницы < 3 секунд
SLA (Service Level Agreement) — это (часто внешний) документ, который формализует наш SLO и последствия нарушения/выполнения.
Зачем устанавливать цель
Превращение "ощущений" в "числа" помогает цифровизации какой-то области знаний. В случае доклада — надежность IT. Это открывает несколько возможностей:
- Можно сравнивать поведение системы в прошлом и в настоящем.
- Можно договориться и сфокусироваться на важном (для заказчика, нас, пользователей) отбросив неважное.
- Можно обнаруживать поломки (зная что именно может ломаться)
- Можно быстрее улучшать пользовательский опыт (зная что им важно)
А также, можно повысить ценность B2B сервиса, за счет лучших предоставляемых условий.
Проблема
Когда появляется количественное значение цели или даже документ, который закрепляет, то появляется соблазн выполнять её во вред другим целям:
Когда мера становится целью, она перестает быть хорошей мерой - Закон Гудхарта
- Искажение приоритетов — команды концентрируются на максимизации метрики вместо достижения истинных целей
- Риски искаженных результатов — подчинение всей деятельности достижению метрики приводит к неэффективным действиям
- Утрата общего видения — упор на одну метрику отвлекает от стратегических целей
- Недооценка контекста — одномерные метрики не учитывают полный контекст ситуации
Как подбирать Цель/SLO
Не все SLO одинаковы. В зависимости от типа компонента системы нужно выбирать разные показатели:
Примеры SLO для разных типов
| Тип SLO | Описание | Пример |
|---|---|---|
| Availability (Доступность) | Процент времени доступности сервиса | 99.9% доступности в течение месяца |
| Latency (Задержка) | Время отклика системы | < 50 мс в 95% случаев |
| Quality (Качество) | Процент корректных ответов | 98% запросов без ухудшения качества |
| Correctness (Корректность) | Точность обработки данных | 99% валидных данных обработано корректно |
| Freshness (Свежесть данных) | Актуальность информации | Обновление каждые 5 минут |
| Throughput (Пропускная способность) | Количество обрабатываемых запросов | 15к запросов в секунду |
| Coverage (Покрытие) | Охват пользователей/функций | 95% пользователей в течение недели |
| Completeness (Полнота) | Полнота обработки данных | 100% данных в 99% времени |
| Durability (Устойчивость) | Надежность хранения | 99.9% вероятность долгосрочного хранения |
Не все SLO одинаковы. В зависимости от типа компонента системы нужно выбирать разные показатели:
| Тип компонента | Подходящие SLO |
|---|---|
| Сервис (API) | Availability, Latency |
| Пайплайн | Correctness, Freshness, Throughput |
| Хранилище | Durability, Coverage, Completeness |
Хочешь научиться правильно работать с инцидентами и не паниковать при сбоях?
Изучай реальные инциденты и развивай навыки диагностики — посмотри коллекцию тренировок на основе реальных сбоев из практики.
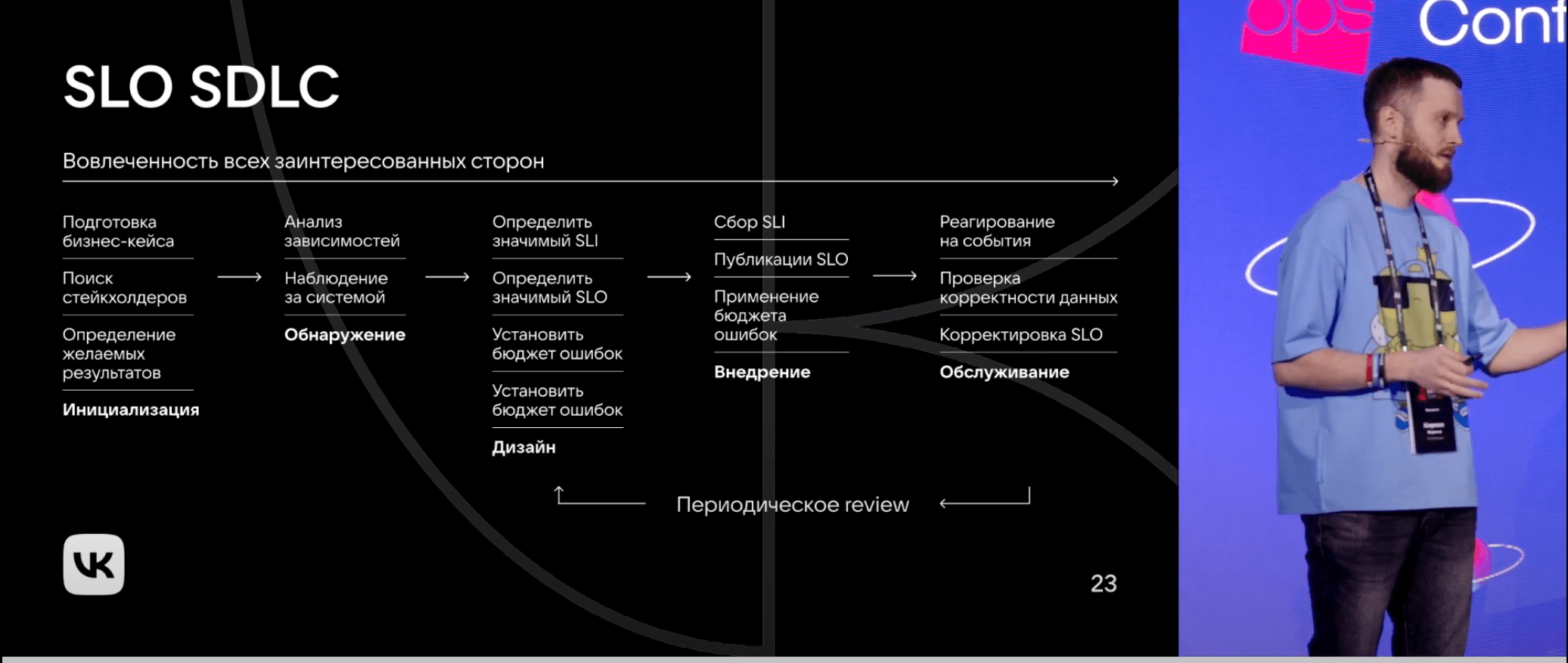
В какой момент выбирать SLO
Кирилл подробно рассказал, как подойти к выбору и наладке SLO. Здесь приводим лишь выжимку.
Как посчитать SLO - формула расчета
IT-система не работает в вакууме, а использует множество компонентов. В этом случае для расчета общего SLO критического пути используется формула:
SLO = Σ(коэффициент × доступность_компонента) / Σ(коэффициенты)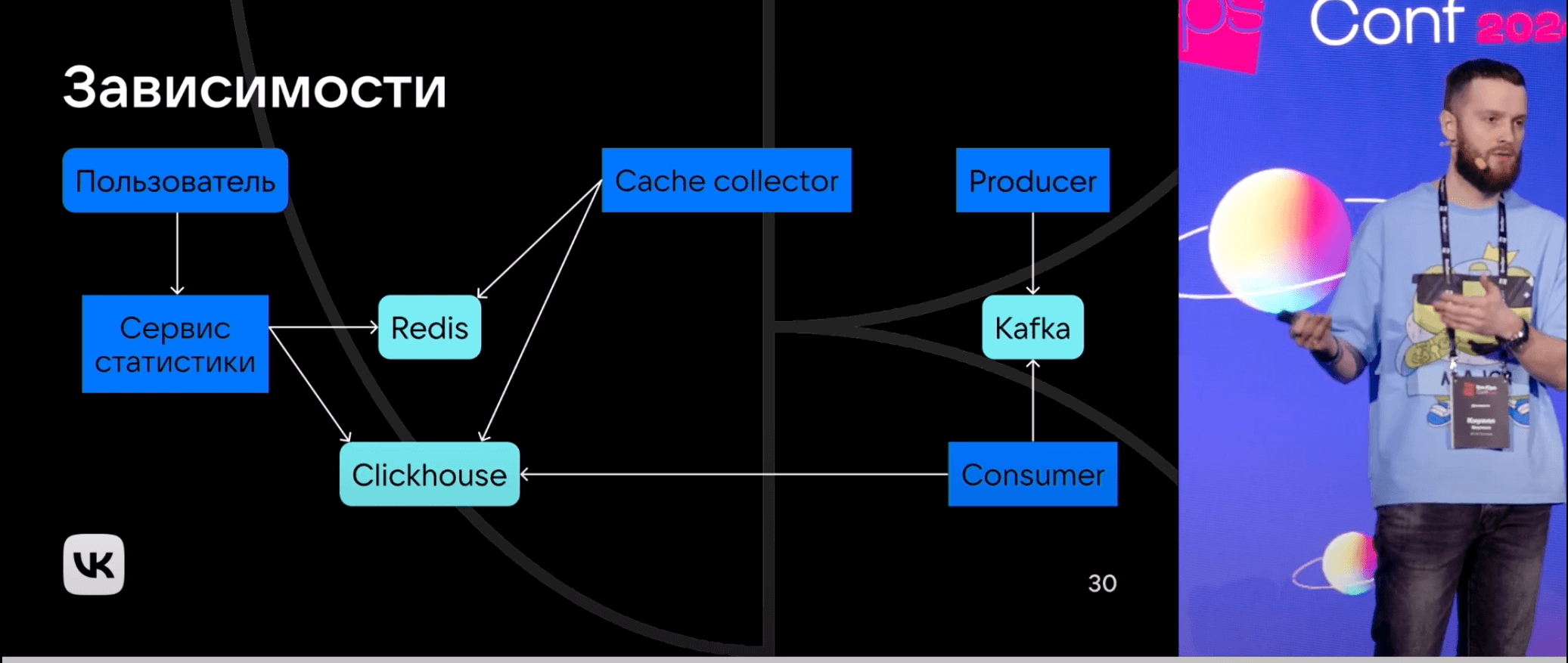
Пример расчета:
- Сервис статистики: вес 0.4, доступность 99.9%
- ClickHouse: вес 0.3, доступность 99.95%
- Redis: вес 0.2, доступность 99.8%
- Kafka: вес 0.1, доступность 99.9%
Итоговый SLO = (0.4×99.9 + 0.3×99.95 + 0.2×99.8 + 0.1×99.9) / 1.0 = 99.89%
FAQ
Что такое "закон Гудхарта" и как его избежать?
Как избежать:
- Используй набор метрик, а не одну
- Связывай SLO с бизнес-целями
- Регулярно пересматривай и валидируй метрики
- Фокусируйся на пользовательском опыте, а не на цифрах
Как правильно выбрать типы SLO для разных компонентов?
Выбор зависит от типа компонента:
- Для сервисов: Availability + Latency
- Для пайплайнов: Correctness + Freshness + Throughput
- Для хранилищ: Durability + Coverage
Используй "меню SLO" — таблицу соответствия типов компонентов и подходящих метрик.
Кто должен инициировать внедрение SLO?
Инициатива должна идти снизу — от инженеров, которые понимают процессы и могут объяснить бизнесу, зачем это нужно. Обычно это SRE-инженеры или DevOps-специалисты.
Как договариваться с бизнесом о SLO?
- Показывай связь с пользовательским опытом
- Используй язык денег и потерь
- Собирай критическое мнение разных команд
- Начинай с анализа текущих проблем пользователей
Что делать, если SLO постоянно нарушаются?
- Проанализируй причины нарушений
- Определи, достижимы ли текущие цели
- Пересмотри SLO с учетом реальных возможностей
- Инвестируй в улучшение архитектуры и процессов