Введение
Надежность — это способность системы выполнять свои функции корректно и предсказуемо в течение определённого времени и в заданных условиях.
Сбои случаются у всех, исследование от New relic говорит, что 50% компаний сталкиваются с инцидентами каждую неделю. Важно не только быстро их устранять, но и уметь предотвращать. Для этого используют два подхода: проактивный и реактивный. Давай разберёмся, в чём их суть, как их применять.
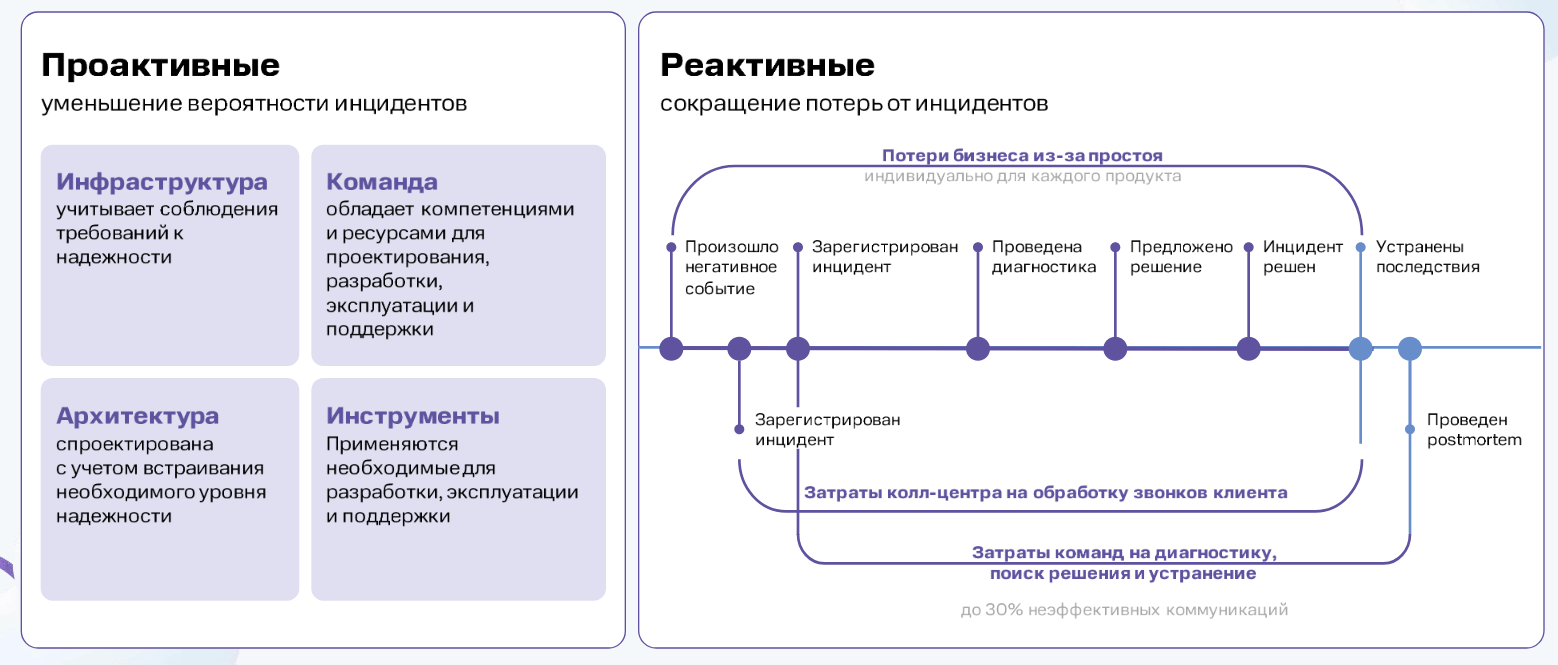
Проактивный подход к обеспечению надежности
Проактивный подход — это стратегия, направленная на снижение вероятности возникновения инцидентов.
Пример работ: внедрение мониторинга и алертинга позволяет выявлять пред-посылки сбоя до того, как они перерастут в серьёзные сбои. Алертить не когда диск на 100% кончился, а алертить при наступлении 50%, 75%, 85%. 95% заполнении (постепенно повышая критичность алерта).
При проактивной работе делается акцент на:
- Инфраструктуру: она строится с учётом требований к отказоустойчивости и масштабируемости. Заранее обдумываем, как будем работать с несколькими копиями приложени
- Архитектуру: проектируем так, чтобы минимизировать точки отказа и обеспечить нужный уровень надёжности. Определяем, недоступность какого компонента приведет к полной деградации.
- Инструменты: используем актуальные средства для мониторинга, автоматизации, тестирования и управления изменениями. Цель - минимизировать человеческое участие для эксплуатации системы.
- Команду: развиваем необходимые компетенции, предоставляем ресурсами для проектирования, разработки и поддержки. Объясняем пользу от работающей системы.
Реактивный подход к обеспечению надежности
Реактивный подход — это стратегия, направленная на минимизацию потерь и времени простоя после возникновения инцидента.
Пример: заранее прописываем в каком порядке будем оповещать участников команды при сбое. От дежурного к владельцу бизнеса.
При реактивном подходе делаем акцент на:
- Быстрое обнаружение инцидентов: описываем состав решения, организуем мониторинг: от того как пользователь начинает взаимодействовать с продуктом, что происходит внутри продукта, как работают системные приложения. Все это с целью максимально быстро сузить область поисков причины сбоя.
- Минимизацию времени на коммуникации: договариваемся о процедуре оповещения, о формате передачи данных между членами команды. Можем применять специализированные ITSM решения, которые этому способствуют.
- Анализ и устранение последствий: не забываем работать с последствиями и причинами сбоя, не просто "починить и забыть", а провести post mortem (пост мортем), где вместе с релевантными коллегами разобрать сбой, предложить идеи для минимизации будущего риска.
Попробуй Incidenta — тренажёр ИТ-инцидентов
Incidenta — это тренажёр для DevOps, SRE и Backend-разработчиков. Ты сможешь прожить десятки реальных сбоев, научиться их диагностировать и не паниковать при очередном ночном алерте. Сценарии тренировок с реальными инцидентами
Как применять проактивный и реактивный подходы: 4 шага
- Оцени риски и требования к надежности — определи, какие инциденты наиболее критичны для твоей системы.
- Внедри инструменты мониторинга и автоматизации — настрой алерты, автоматические проверки, CI/CD.
- Обучи команду реагированию на инциденты — проводи разборы инцидентов
- Анализируй инциденты и улучшай процессы — после каждого сбоя проводи postmortem и внедряй улучшения (а не просто клади в backlog)
FAQ
Что такое проактивный подход к обеспечению надежности?
Проактивный подход — это стратегия, направленная на предотвращение инцидентов с помощью правильной архитектуры, инфраструктуры, инструментов и обучения команды.
Что такое реактивный подход к обеспечению надежности?
Реактивный подход — это стратегия, при которой основное внимание уделяется быстрому реагированию на инциденты, их диагностике и устранению последствий.
Какой подход лучше: проактивный или реактивный?
Лучший результат достигается при сочетании обоих подходов: проактивный снижает вероятность сбоев, реактивный — минимизирует потери при их возникновении.
Какие инструменты помогают в обеспечении надежности?
Мониторинг (Prometheus, Victoria Metrics, Grafana), автоматизация (Ansible, Terraform), системы управления инцидентами (ITSM), тренажёры инцидентов (Incidenta).